Распространенные технические ошибки сайтов





Содержание:
Сайт может работать даже с техническими ошибками, но существуют проблемы, которые не дают веб-ресурсу подниматься в топ поисковой выдачи и отрезают его от органического трафика. Рассмотрим распространенные ошибки, которые допускают разработчики, и расположим их по степени влияния на видимость. Первыми в каждом блоке станут самые опасные для сайта. Начнем с Яндекса, поскольку он приоритетен для России. Затем опишем распространенные ошибки в Google, ведь этот поисковик остается популярным, поэтому игнорировать продвижение в нем будет неправильно. В конце статьи приведем общие недочеты, которые может допустить вебмастер.
Ошибки из Яндекс.Вебмастера
Яндекс предоставляет своим вебмастерам информативную панель, которая позволяет быстро находить ошибки. Рекомендуем тщательно следить за предупреждениями системы.
Недостаточно качественные страницы
Подобный статус получают документы, которые по мнению Яндекса не имеют ценности для пользователя. Из-за такой оценки страницам запрещено участвовать в распределении мест в топе выдачи. Найти такие страницы можно в Яндекс.Вебмастере. Зайдите в «Индексирование», кликните на «Страницы в поиске», найдите «Исключенные», нажмите фильтр «Недостаточно качественные».
Например, недостаточно качественными система может посчитать страницы-дубли с get-параметрами. Также из-за «некачественности» может быть исключен технический файл (robots.txt). Обычно в список исключенных из поиска попадают страницы с техническими ошибками: мало контента, ошибки в листинге, плохо заполненные карточки товара, некорректный ответ сервера и пр.
Дубли
Страницы, у которых полностью идентичное содержимое, но разные url. Яндекс выберет ту страницу, у которой адрес окажется короче. Именно ее он включит в поиск.
От таких ошибок нужно избавляться, используя способы, которые рекомендует сам Яндекс (редирект, замена контента или канонический адрес). С течением времени, если вы исправите недочеты, отчеты о них пропадут из Вебмастера.
Ошибка HTTP: 404
Яндекс указывает, что обнаружил на вашем сайт неработающую страницу. Нужно восстанавливать подобные страницы, особенно если раньше они давали трафик вашему сайту или имели важные бэклинки. В тех случаях, когда возвратить ее уже невозможно, нужно настроить 301 редирект на url, который похож по контенту на отсутствующий. Некоторые вебмастеры настраивают перенаправление удаленных карточек товара (ставших 404) на главную страницу или товарную категорию. Но эта стратегия может привести к появлению отчета Soft 404 в консоли Google. Соответственно, это не выход, если вы хотите как можно реже сталкиваться с ошибками в продвижении сайта.
Неканонические страницы
Если страницы содержат похожий или полностью одинаковый контент, их связывают в одну группу. Вебмастер выбирает среди них основную, прописывает в ее атрибуте строку rel=canonical. Она будет главной, а все остальные, менее важные, изымаются из поисковой выдачи.
Рекомендации, что делать с подобными страницами: регулярно проверяйте, верно ли определена каноническая страница, исключены ли все второстепенные.
Не получилось скачать страницу
Отчет содержит ссылки на страницы, которые у него не получилось скачать. Например, они не были доступны или запрещено сканирование.
Чтобы избавиться от ошибки, просмотрите ответ сервера (заголовки и код), проверьте метатеги, запрещающие сканирование и индексирование страниц. Природа исключенных страниц в Google Search Console обычно совпадает с аналогами в Яндексе. Очень многие из этих страниц – зомби, которые не приводят трафик и не имеют никаких перспектив. Такие ошибки технического плана фиксируются к панели Яндекса. Важно не игнорировать отчеты с подобными страницами, если вы рассчитываете на органический трафик из Яндекса.
Ошибки из отчетов Google Search Console
Все приведенные ниже ошибки нужно исправлять, чтобы получить хорошие позиции в выдаче и увеличить объем трафика.
Ошибки при сканировании отправленного url
Сканирование сайта с ошибкой возможно в силу различных причин. Например, специфика настройки CMS, неправильная отработка DNS, заголовки и теги с запретом индексации. Обычно подобные ошибки случаются с url, которые отправили на принудительную индексацию.
Узнать, почему Google отказывается сканировать страницу, можно с помощью обычной проверки статуса url. Необходимо уточнить, как отвечает сервер. Когда проблем не обнаружено, можно еще раз отправить страницу, чтобы система ее проиндексировала.
Ошибка переадресации
Отчет об этой ошибке появляется из-за неправильного формата url или слишком длинной цепочки перенаправлений.
Чтобы избавиться от этой недоработки, уберите лишние части в цепочках или доведите url до требуемого формата. Редиректы становятся проблемой, когда в адресах содержатся не только буквы латинского алфавита, а вообще все символы из контентных заголовков.
Как исправить:
- настраивайте переадресацию только для тех страниц, которые важны для привлечения трафика;
- закройте кодом 410 страницы, которые созданы случайно и не смогут в дальнейшем привести трафик на сайт.
Заботьтесь о том, чтобы url был сформирован правильно еще на первых стадиях разработки сайта.
Тег noindex в отправленной на сканирование странице
Представляет собой одну из важных причин проблем со сканированием. Название ошибки говорит само за себя: в отправленной на индексацию странице прописан запрещающий метатег или заголовок.
Чтобы узнать, в чем проблема, нужно проверить код страницы или ответ сервера. Случается, что ошибка не исчезает даже после того, как вебмастер убирает noindex. Что это значит? Консоль Google пока что не обновилась, нужно подождать. Специалист способен немного помочь роботу с обнаружением изменений на страницах, нужно отправить их на переиндексацию.
Url отдает ложную ошибку 404
Одна из ошибок, которые сложно объяснить: она указывает на то, что неправильно настроен код ответа сервера, но при этом на самом деле связи нет вообще никакой.
Почему она возникает:
- на странице ничего нет или совсем мало контента;
- человеку показывается заглушка 404, сервер передает роботу ответ 200 OK;
- на странице нормальное количество контента, критических ошибок нет, но ее содержимое преимущественно составлено из неработающих или закрытых через robots.txt скриптов и стилей.
Как избавиться от подобной ошибки в консоли:
- проверить, корректный ли ответ отдает сервер (обратите внимание на User-agent робота Google);
- убедиться, что Google правильно видит контент на страницах (используйте для этого инструмент проверки адресов).
Доступ к отправленному на сканирование url заблокирован в robots.txt
Подобное уведомление появляется, когда адрес, который вы закрыли от индексации, на самом деле виден для поисковой системы. Такая ситуация происходит, когда на скрытую от робота страницу часто ссылаются на других сайтах. При этом в других случаях поисковая система будет выполнять правила из вашего robots.txt.
Как избавиться от ошибки? Используйте другие способы запрета. Например, пропишите метатег или настройте ответ сервера, в котором будет X-Robots-Tag: noindex.
Дубль текста на страницах пагинации
Сейчас действует тренд на открытие страниц пагинации для индексирования. Поэтому не следует использовать один и тот же текст на всех подобных страницах. Несмотря на то, что качество и даже наличие seo-текста в интернет-магазине может быть сомнительным, копировать один и тот же контент, чтобы «закрыть дыру», нельзя.
Редиректы
- Большое количество перенаправлений
- проверьте сайт с помощью десктопного краулера;
- найдите документы с 30* ответом;
- найдите страницы-источники;
- поменяйте все страницы с 30* ответом на актуальные цели для редиректа.
- Использование 302 ответа вместо 301
Редиректы в целом не ошибка. Однако их избыточность провоцирует дополнительную нагрузку на сканирующего робота поисковой системы. Как исправлять такую ситуацию:
Ответ 301 передает роботу поисковой системы, что содержащийся на странице контент теперь расположен по другому адресу. Код 302 показывает боту, что адрес контента сменился не навсегда, а временно. Настраивать редирект 302 уместно, когда в разделе или на конкретной странице сейчас ведутся технические работы. Когда-нибудь они закончатся, и робот при очередном сканировании увидит возвратившееся содержимое, которое нужно проанализировать. Лучше сразу выставлять правильные редиректы, потому что обычно заранее известно, убирает вебмастер контент насовсем или только временно.
Отсутствие Alt и Title у изображений
Для усиления релевантности страницы необходимо прописывать атрибуты изображений. Содержимое Alt и Title не должно дублироваться, при этом в нем обязательно должны быть ключевые слова. Благодаря Alt робот-сканер определит, что именно изображено на картинке. Даже с учетом того, что у Title меньше функций, его тоже стоит заполнить.
Что нужно сделать для проверки Alt вашей страницы:
- использовать парсер для сканирования сайта/страницы, чтобы найти все изображения без атрибута Alt;
- вручную исследовать код страницы;
- просканировать страницу через https://validator.w3.org/.
Если используете последний вариант, нажмите на «image report», чтобы отображались данные о картинках.
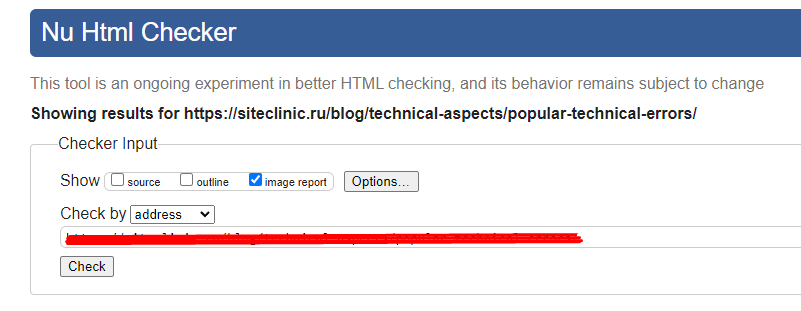
Отчет по изображениям отображается в самом низу страницы вместе с предупреждениями об ошибках.
Заказать
коммерческое предложениеСтатьи по теме


